
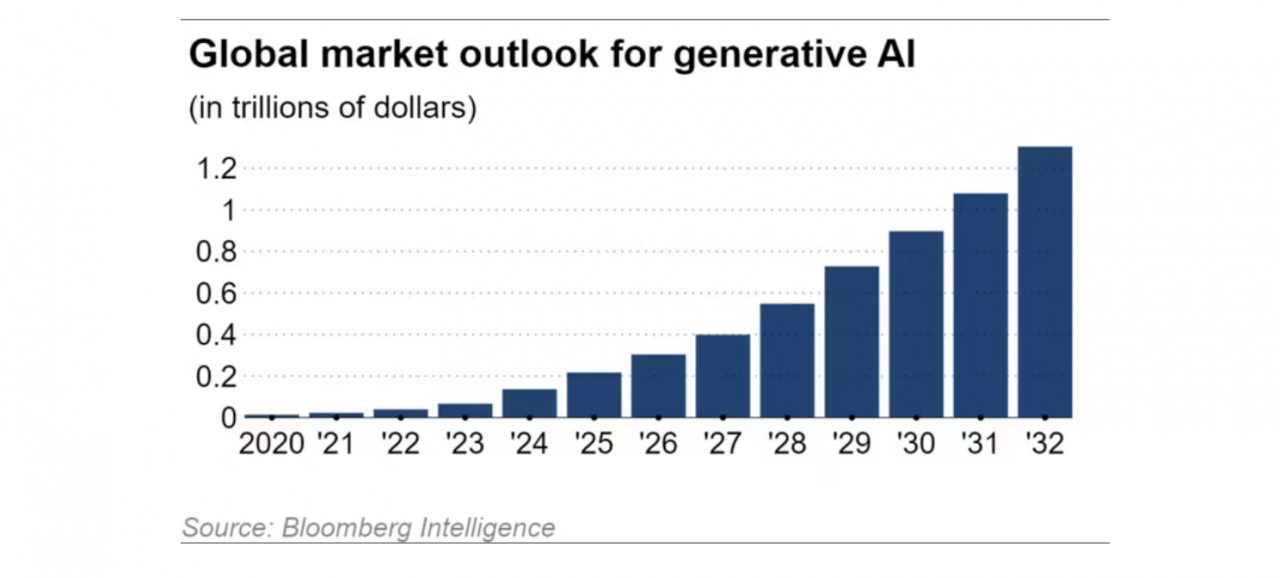
Le marché mondial de l'IA synthétique connaît une croissance annuelle de 42 %, selon les estimations de Bloomberg Intelligence, et devrait atteindre 1,3 billion de dollars d'ici 2032, soit environ 32 fois sa taille de 40 milliards de dollars en 2022.
Les entreprises technologiques américaines comme OpenAI, Google et Amazon, des géants de la technologie dotés de moyens importants et de talents, ouvrent la voie.
Malgré une concurrence intense, VinGroup a choisi de développer sa propre version, en utilisant les données vietnamiennes pour créer une IA avec une précision supérieure à celle des concurrents étrangers, a déclaré Vu Ha Van, professeur de mathématiques à l'Université de Yale et directeur scientifique de VBD.
À ce jour, les programmes d’IA générative ont été formés principalement sur des données en anglais. Cela signifie qu’il existe relativement peu de données sur le Vietnam, ce qui réduit la précision de ces programmes en ce qui concerne la culture, l’histoire et les lois locales.
Le grand modèle de langage (LLM) de ViGPT serait composé de 1,6 milliard de paramètres, soit quelques pour cent de la taille du GPT-4 d'OpenAI.
Plus de paramètres correspondent généralement à une intelligence plus élevée. Mais selon l'évaluation générale de l'IA personnalisée pour le marché vietnamien, ViGPT a surpassé de nombreux concurrents étrangers et a obtenu un score juste derrière ChatGPT.
Le groupe VinFast appliquera la technologie de l’IA à la production de véhicules électriques. Le conducteur pourra contrôler le véhicule grâce à des commandes verbales vietnamiennes. Le groupe prévoit également d’intégrer l’IA dans la finance, l’assurance et la logistique.
La course au développement de l'IA en Asie
On estime que seulement 5 % environ de la population mondiale parle l’anglais comme première langue, ce qui signifie qu’il existe un énorme besoin potentiel d’IA développée pour les locuteurs non natifs de l’anglais.
Au Japon, les entreprises développent une IA qui génère du japonais. En août, la société d'électronique NEC a lancé un service utilisant LLM cotomi. La société de télécommunications NTT lancera en mars un service basé sur Tsuzumi, un autre LLM. L'opérateur mobile japonais SoftBank développe également son propre LLM.
« Comprendre les pratiques commerciales japonaises nous donne des avantages en termes de convivialité, comme répondre aux e-mails et effectuer le travail du centre d'appels de manière plus naturelle », a déclaré Junichi Miyakawa, président de SoftBank.
Les risques d’une dépendance excessive à l’égard des États-Unis, notamment en matière de compétitivité internationale et de sécurité nationale, alimentent la course au développement d’une IA indigène. On craint également que l’utilisation de programmes d’IA développés dans d’autres pays n’entraîne des violations de données, affectant des informations sensibles.
Le professeur Van a déclaré que les technologies émergentes ne devraient pas être laissées aux entreprises étrangères, car de plus en plus d'étudiants utilisent l'IA pour étudier, ce qui signifie que l'innovation a un impact énorme sur la jeune génération.
En Chine, qui est en concurrence avec les États-Unis en matière de technologie, Baidu, Tencent Holdings et Alibaba Group Holding développent une IA innovante. Ernie Bot de Baidu comptait plus de 100 millions d'utilisateurs à la fin de l'année dernière.
« Le modèle de langage génératif à grande échelle que nous développons actuellement sera plus adapté à la langue chinoise et au marché chinois », a déclaré Robin Li, président-directeur général de Baidu.
En août dernier, la société sud-coréenne de services Web Naver a dévoilé HyperClova X, une IA synthétique personnalisée pour la langue coréenne. Le programme sera intégré au moteur de recherche et à la plateforme d'achat en ligne de l'entreprise pour permettre aux utilisateurs de trouver plus efficacement les résultats qu'ils souhaitent.
Naver affirme que sa base de données coréenne est 6 500 fois plus grande que celle de ChatGPT, ce qui permet une lecture de texte plus naturelle et une reconnaissance linguistique plus fluide.
Le mois dernier, Singapour a annoncé son intention de développer des LLM adaptés aux langues indonésienne, malaisienne et thaïlandaise. Cependant, de telles initiatives seront confrontées à des défis, tels que le manque de données pouvant être formées dans des langues moins utilisées et la rentabilité du développement de tels modèles.

Source

























































































Comment (0)