
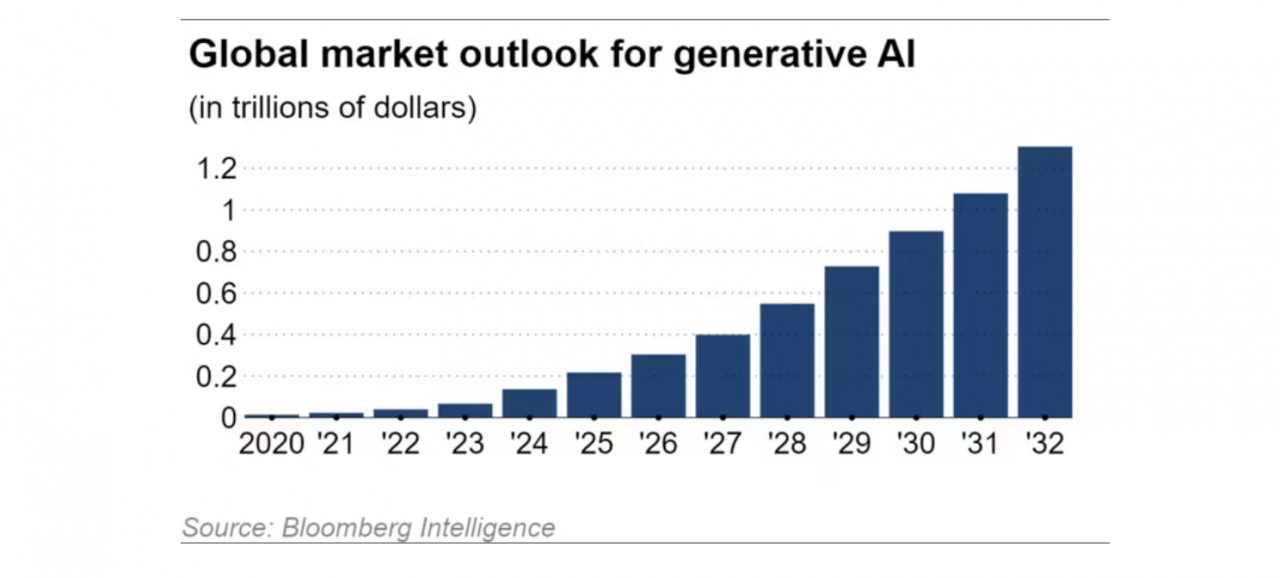
블룸버그 인텔리전스의 추정에 따르면 합성 AI의 글로벌 시장은 연간 42%씩 확대되고 있으며, 2032년에는 1조 3,000억 달러에 도달할 것으로 예상됩니다. 이는 2022년 시장 규모인 400억 달러의 약 32배에 해당합니다.
이러한 추세를 선도하는 것은 OpenAI, Google, Amazon과 같은 미국의 기술 기업들입니다. 이들은 막대한 자금력과 인재를 보유한 기술 거대 기업입니다.
예일대학교 수학과 교수이자 VBD의 최고 과학 책임자인 부 하 반(Vu Ha Van)은 치열한 경쟁에도 불구하고 VinGroup은 베트남 데이터를 활용하여 외국 경쟁사보다 정확도가 높은 AI를 만드는 자체 버전을 개발하기로 결정했다고 말했습니다.
현재까지 생성 AI 프로그램은 주로 영어 데이터를 대상으로 훈련되었습니다. 즉, 베트남에서 얻은 데이터가 상대적으로 적고, 이로 인해 현지 문화, 역사, 법률에 대한 프로그램의 정확도가 떨어집니다.
ViGPT의 대규모 언어 모델(LLM)은 16억 개의 매개변수로 구성되어 있다고 하는데, 이는 OpenAI의 GPT-4 크기의 몇 퍼센트에 불과합니다.
일반적으로 매개변수가 많을수록 지능이 더 높다는 뜻입니다. 그러나 베트남 시장에 맞춰진 일반적인 AI 평가에 따르면 ViGPT는 많은 외국 경쟁사보다 우수한 성과를 보였으며 ChatGPT에 이어 두 번째 점수를 달성했습니다.
VinFast 그룹이 전기차 생산에 AI 기술을 적용할 예정이다. 운전자는 베트남어 음성 명령을 통해 차량을 제어할 수 있습니다. 이 그룹은 또한 AI를 금융, 보험, 물류에 접목할 계획입니다.
아시아의 AI 개발 경쟁
전 세계 인구의 약 5%만이 영어를 모국어로 사용하는 것으로 추정되는데, 이는 영어가 모국어가 아닌 사람을 위해 개발된 AI에 대한 잠재적 수요가 엄청나다는 것을 의미합니다.
일본 기업들은 일본어를 생성하는 AI를 개발하고 있습니다. 8월에 전자 회사 NEC는 LLM cotomi를 이용한 서비스를 시작했습니다. 통신 회사 NTT는 또 다른 LLM인 츠즈미를 기반으로 3월에 서비스를 시작할 예정입니다. 일본 이동통신사 소프트뱅크도 자체 LLM을 개발하고 있습니다.
소프트뱅크 사장인 준이치 미야카와는 "일본의 비즈니스 관행을 이해하면 이메일에 응답하고 콜센터 업무를 보다 자연스럽게 수행하는 등 사용성 측면에서 이점이 있습니다." 라고 말했습니다.
토착 AI 개발 경쟁을 가속화하는 것은 특히 국제 경쟁력과 국가 안보와 관련하여 미국에 지나치게 의존하는 데 따른 위험입니다. 다른 국가에서 개발된 AI 프로그램을 사용하면 데이터 침해로 인해 민감한 정보가 영향을 받을 수 있다는 우려도 있습니다.
반 교수는 점점 더 많은 학생들이 AI를 이용해 공부하고 있기 때문에 새로운 기술을 외국 기업에 맡겨서는 안 된다고 말했습니다. 이는 혁신이 젊은 세대에 큰 영향을 미친다는 것을 의미합니다.
기술 분야에서 미국과 경쟁하고 있는 중국에서는 바이두, 텐센트 홀딩스, 알리바바 그룹 홀딩스가 혁신적인 AI를 개발하고 있습니다. 바이두의 어니 봇은 작년 말 현재 1억 명이 넘는 사용자를 자랑했습니다.
바이두 회장 겸 CEO인 로빈 리(Robin Li) 는 "우리가 지금 개발 중인 생성적 대규모 언어 모델은 중국어와 중국 시장에 더 적합할 것"이라고 말했다.
작년 8월, 한국의 웹 서비스 회사 네이버는 한국어에 맞춰 개발된 합성 AI인 HyperClova X를 공개했습니다. 이 프로그램은 회사의 검색 엔진과 온라인 쇼핑 플랫폼과 통합되어 사용자가 원하는 결과를 더욱 효율적으로 찾을 수 있게 해줍니다.
네이버는 자사의 한국어 데이터베이스가 ChatGPT의 한국어 데이터베이스보다 6,500배 더 크기 때문에 더 자연스럽게 읽히는 텍스트와 더 매끄러운 언어 인식이 가능하다고 밝혔습니다.
지난달 싱가포르는 인도네시아어, 말레이시아어, 태국어에 맞춰 LLM을 개발할 계획을 발표했습니다. 그러나 이러한 이니셔티브는 덜 사용되는 언어로 학습 가능한 데이터가 부족하고 해당 모델을 개발하는 데 따른 수익성이 낮은 등의 문제에 직면하게 될 것입니다.

[광고2]
원천

























































































댓글 (0)