
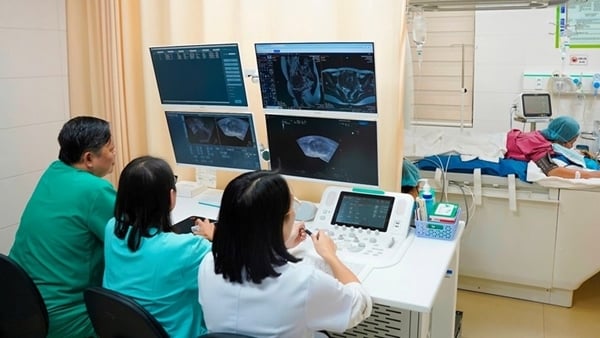
Die Technologiegiganten Alibaba, Baidu und ByteDance liefern sich ein Wettrennen um die Kosten für „Inferenz“-KI und bieten Preise an, die 90 Prozent unter denen ihrer US-amerikanischen Konkurrenten liegen.
Festlandunternehmen senken ihre Kosten, indem sie Modelle entwickeln, die auf kleineren Datenmengen trainiert werden und weniger Rechenleistung, dafür aber optimierte Hardware benötigen, sagt Lee Kai-Fu, Gründer von 01.ai und ehemaliger Chef von Google China.
Laut der kürzlich von UC Berkeley SkyLab und LMSYS veröffentlichten Rangliste belegte das Yi-Lingtning-Modell des Startups 01.ai den dritten Platz, gleichauf mit Grok-2 von x.AI, hinter OpenAI und Google. Dieses Ranking basiert auf den Bewertungen der Benutzer zu den Antworten auf die Abfragen.

01.ai und DeepSeek sind KI-Unternehmen vom chinesischen Festland, die sich bei der Schulung von Modellen auf kleinere Datensätze konzentrieren und gleichzeitig günstige, hochqualifizierte Arbeitskräfte einstellen.
Laut FT betragen die Inferenzkosten von Yi-Lightning 14 Cent pro Million Token, verglichen mit 26 Cent für OpenAIs o1-mini GPT. Mittlerweile betragen die Kosten für GPT 4o bis zu 4,4 USD pro Million Token. Die Anzahl der zum Generieren der Antwort verwendeten Token hängt von der Komplexität jeder Abfrage ab.
Der Gründer von Yi-Lightning gab bekannt, dass das Unternehmen 3 Millionen US-Dollar für die „Erstschulung“ ausgegeben habe, bevor es Feinabstimmungen für verschiedene Anwendungsfälle vornahm. Lee sagte, ihr Ziel sei es nicht, „das beste Modell zu entwickeln“, sondern ein Konkurrenzmodell zu bauen, das „fünf bis zehn Mal billiger“ sei.
Die von 01.ai, DeepSeek, MiniMax und Stepfun angewandte Methode wird als „Expertenmodellierung“ bezeichnet – es handelt sich dabei einfach um die Kombination mehrerer neuronaler Netzwerke, die anhand domänenspezifischer Datensätze trainiert wurden.
Forscher sehen in diesem Ansatz einen wichtigen Weg, um mit weniger Rechenleistung das gleiche Maß an Intelligenz wie bei Big-Data-Modellen zu erreichen. Die Schwierigkeit bei diesem Ansatz besteht jedoch darin, dass die Ingenieure den Trainingsprozess mit „mehreren Experten“ orchestrieren müssen, anstatt nur mit einem allgemeinen Modell.
Aufgrund der Schwierigkeiten beim Zugang zu High-End-KI-Chips haben sich chinesische Unternehmen der Entwicklung hochwertiger Datensätze zugewandt, mit denen sie Expertenmodelle trainieren und so mit westlichen Konkurrenten konkurrieren.
Lee sagte, 01.ai verfüge über unkonventionelle Methoden zum Sammeln von Daten, etwa das Scannen von Büchern oder das Sammeln von Artikeln in der Messaging-App WeChat, die im offenen Web nicht zugänglich seien.
Der Gründer ist davon überzeugt, dass China mit einem riesigen Pool an günstigen technischen Talenten besser aufgestellt sei als die USA.
(Laut FT, Bloomberg)

[Anzeige_2]
Quelle: https://vietnamnet.vn/trung-quoc-giam-90-chi-phi-ai-suy-luan-so-voi-my-2334520.html



![[Foto] Alle Schwierigkeiten überwunden, Baufortschritt beim Erweiterungsprojekt des Wasserkraftwerks Hoa Binh beschleunigt](https://vstatic.vietnam.vn/vietnam/resource/IMAGE/2025/4/12/bff04b551e98484c84d74c8faa3526e0)

![[Foto] Abschluss der 11. Konferenz des 13. Zentralkomitees der Kommunistischen Partei Vietnams](https://vstatic.vietnam.vn/vietnam/resource/IMAGE/2025/4/12/114b57fe6e9b4814a5ddfacf6dfe5b7f)

















































































Kommentar (0)