

La GPU es el cerebro de la computadora con inteligencia artificial
En pocas palabras, la unidad de procesamiento gráfico (GPU) actúa como el cerebro de la computadora de IA.
Como ya sabéis, la unidad central de procesamiento (CPU) es el cerebro de la computadora. La ventaja de una GPU es que es esencialmente una CPU especializada en realizar cálculos complejos. La forma más rápida de realizar este cálculo es hacer que grupos de GPU resuelvan el mismo problema. Aun así, entrenar un modelo de IA puede llevar semanas o incluso meses. Una vez construido, se coloca en el sistema informático front-end y los usuarios pueden hacer preguntas al modelo de IA, un proceso llamado inferencia.
Una computadora de IA que contiene múltiples GPU
La mejor arquitectura para resolver problemas de IA es utilizar un grupo de GPU en un rack, conectado a un conmutador en la parte superior del rack. Se pueden conectar adicionalmente varios racks de GPU en una jerarquía de conexión de red. A medida que los problemas a resolver aumentan en complejidad, los requisitos de GPU también aumentan y algunos proyectos pueden tener que implementar clústeres de miles de GPU.
Cada clúster de IA es una red pequeña
Al construir un clúster de IA, es necesario configurar una pequeña red de computadoras para conectar y permitir que las GPU trabajen juntas y compartan datos de manera eficiente.
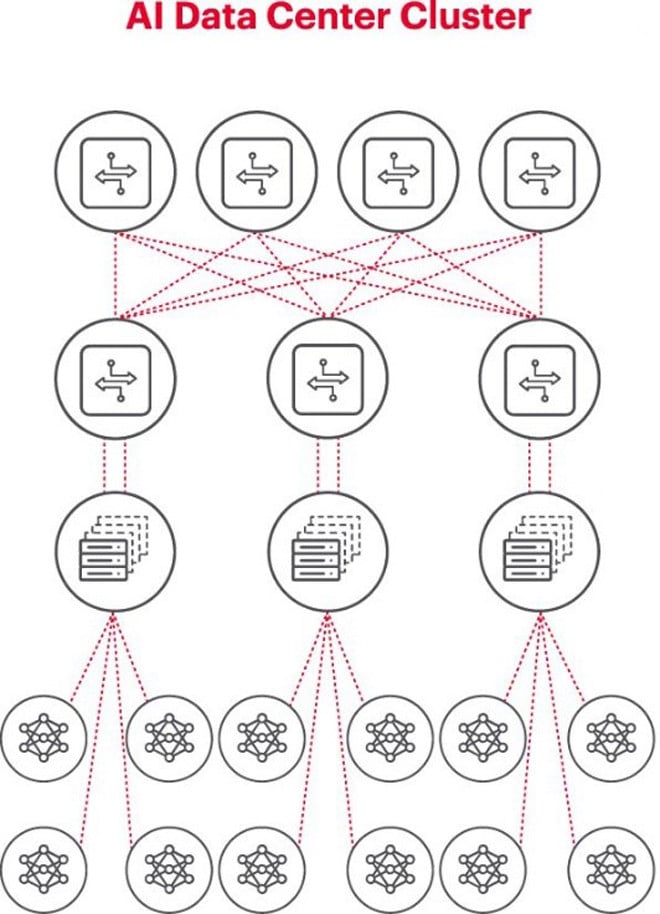
La figura de arriba ilustra un clúster de IA donde los círculos en la parte inferior representan flujos de trabajo que se ejecutan en GPU. La GPU se conecta a los conmutadores en la parte superior del rack (ToR). Los conmutadores ToR también se conectan a los conmutadores de red troncal que se muestran arriba del diagrama, lo que demuestra una jerarquía de red clara necesaria cuando hay varias GPU involucradas.
Las redes son un cuello de botella en la implementación de la IA
El otoño pasado, en la Cumbre Global del Open Computer Project (OCP), donde los delegados trabajaron juntos para construir la próxima generación de infraestructura de IA, el delegado Loi Nguyen de Marvell Technology planteó un punto clave: “la red es el nuevo cuello de botella”.
Técnicamente, grandes retrasos de paquetes o pérdidas de paquetes debido a la congestión de la red pueden provocar que los paquetes se reenvíen, lo que aumenta significativamente el tiempo de finalización del trabajo (JCT). Como resultado, millones o decenas de millones de dólares en GPU de las empresas se desperdician debido a sistemas de IA ineficientes, lo que causa daños a las empresas tanto en ingresos como en tiempo de comercialización.
La medición es una condición clave para el funcionamiento exitoso de las redes de IA
Para ejecutar de manera eficiente un clúster de IA, las GPU deben poder utilizarse por completo para acortar los tiempos de entrenamiento e implementar modelos de aprendizaje para maximizar el retorno de la inversión. Por lo tanto, es necesario probar y evaluar el rendimiento del clúster de IA (Figura 2). Sin embargo, esta tarea no es fácil, porque en términos de arquitectura del sistema hay muchas configuraciones y relaciones entre la GPU y las estructuras de red que necesitan complementarse entre sí para manejar el problema.
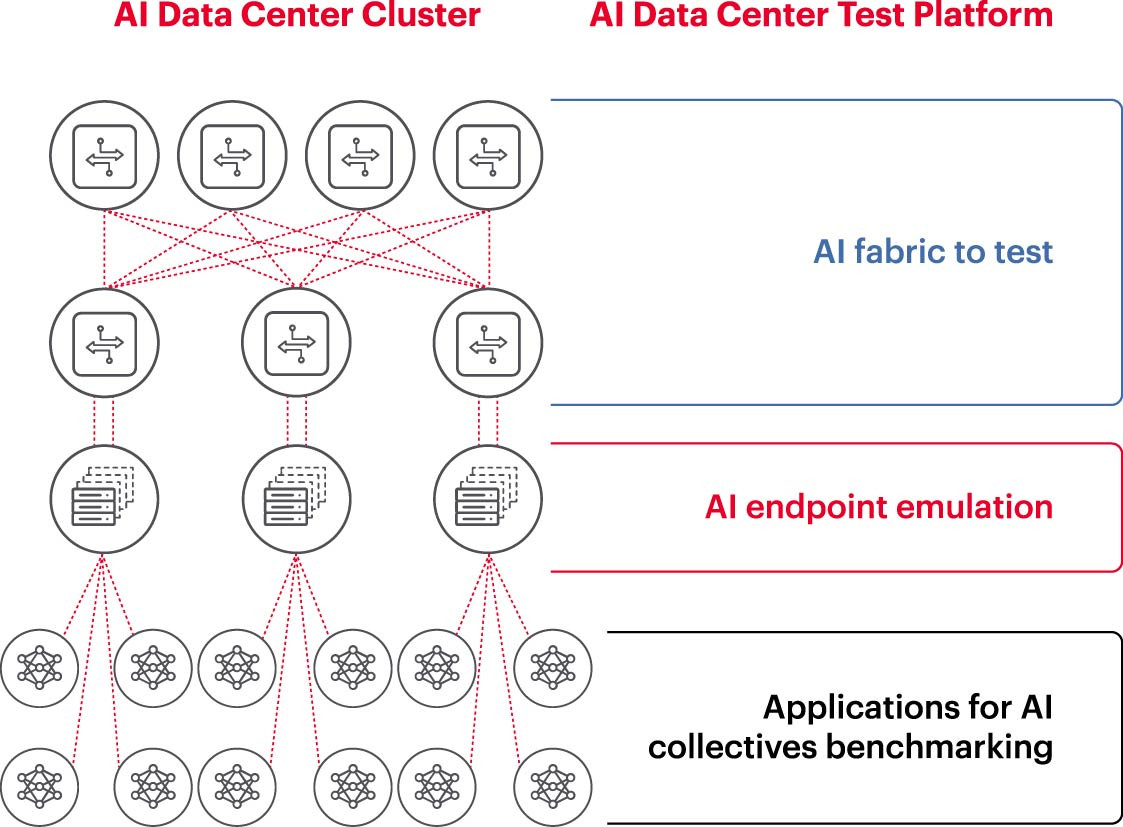
Esto crea muchos desafíos a la hora de medir las redes de IA:
- Dificultad para reproducir redes de producción enteras en el laboratorio debido a limitaciones de costos, equipos, escasez de ingenieros de IA de red capacitados, espacio, energía y temperatura.
- La medición en el sistema de producción reduce la capacidad de procesamiento disponible del propio sistema de producción.
- Dificultad para reproducir con precisión los problemas debido a las diferencias en la escala y el alcance de los mismos.
- La complejidad de cómo las GPU están conectadas colectivamente.
Para abordar estos desafíos, las empresas pueden probar un subconjunto de las configuraciones propuestas en un entorno de laboratorio para comparar parámetros clave como JCT (tiempo de finalización del trabajo), el ancho de banda que el equipo de IA puede lograr y compararlo con la utilización de la plataforma de conmutación y la utilización de caché. Este punto de referencia ayuda a encontrar el equilibrio adecuado entre la carga de trabajo de procesamiento/GPU y el diseño/configuración de la red. Una vez satisfechos con los resultados, los arquitectos de computadoras y los ingenieros de redes pueden aplicar estas configuraciones a la producción y medir nuevos resultados.
Los laboratorios de investigación corporativos, los institutos de investigación y las universidades están trabajando para analizar cada aspecto de la construcción y el funcionamiento de redes de IA efectivas para abordar los desafíos de trabajar en redes grandes, especialmente a medida que las mejores prácticas continúan cambiando. Este enfoque colaborativo repetible es la única forma en que las empresas pueden realizar mediciones repetibles y probar rápidamente escenarios hipotéticos: la base para optimizar las redes para la IA.
(Fuente: Keysight Technologies)
Fuente: https://vietnamnet.vn/ket-noi-mang-ai-5-dieu-can-biet-2321288.html




































![[Foto] El Primer Ministro Pham Minh Chinh preside la Conferencia del Gobierno con las localidades sobre el crecimiento económico](https://vstatic.vietnam.vn/vietnam/resource/IMAGE/2025/2/21/f34583484f2643a2a2b72168a0d64baa)






















































Kommentar (0)