
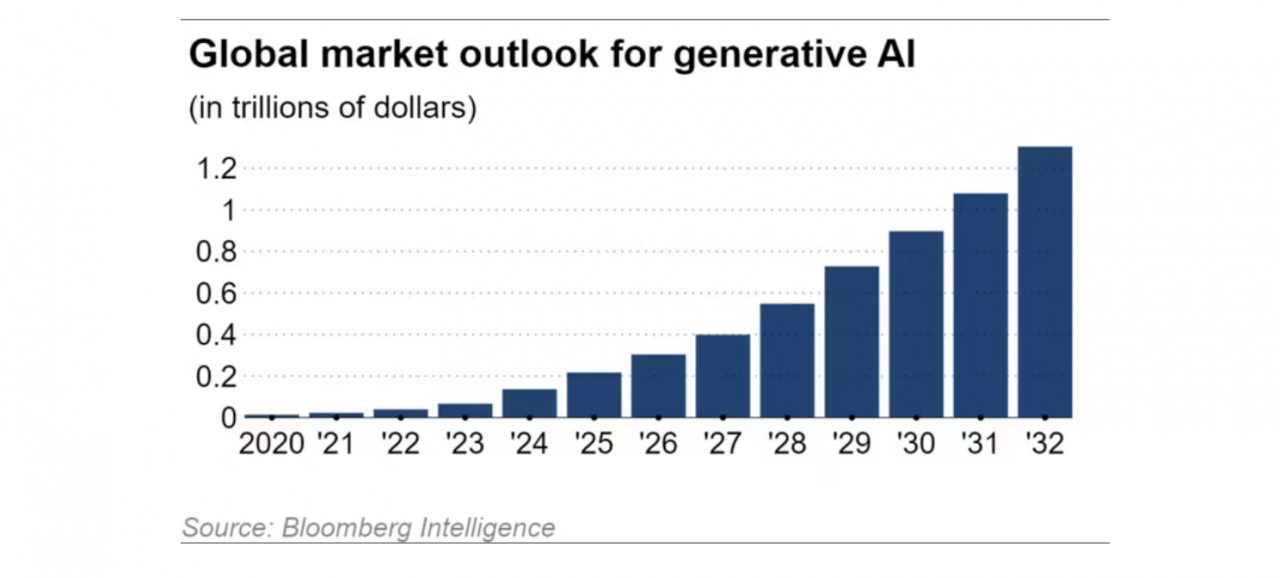
ブルームバーグ・インテリジェンスの推計によると、合成AIの世界市場は年間42%拡大しており、2032年までに1兆3000億ドルに達すると予想されている。これは2022年の400億ドル規模の約32倍にあたる。
先頭に立っているのは、OpenAI、Google、Amazonといった米国のテクノロジー企業で、潤沢な資金と才能を備えた巨大テクノロジー企業だ。
激しい競争にもかかわらず、 ビングループはベトナムのデータを使い、海外の競合企業よりも精度の高いAIを作るために独自のバージョンを開発することを選んだと、VBDの最高科学責任者を務めるイェール大学の数学教授、ヴー・ハ・ヴァン氏は述べた。
これまで、生成 AI プログラムは主に英語のデータに基づいてトレーニングされてきました。つまり、ベトナムからのデータは比較的少なく、地元の文化、歴史、法律に関してはこれらのプログラムの精度が低下します。
ViGPTの大規模言語モデル(LLM)は16億のパラメータで構成されていると言われており、これはOpenAIのGPT-4のサイズの数パーセントに相当します。
通常、パラメータが多いほど、知能が高くなります。しかし、ベトナム市場向けにカスタマイズされた一般的な AI 評価によると、ViGPT は多くの海外の競合他社を上回り、ChatGPT に次ぐスコアを達成しました。
VinFastグループはAI技術を電気自動車生産に応用する。運転手はベトナム語の口頭指示を通じて車両を制御できるようになります。同グループは金融、保険、物流にもAIを取り入れる計画だ。
アジアにおけるAI開発競争
世界人口のうち英語を母国語とする人はわずか5%程度と推定されており、英語を母国語としない人向けに開発された AI の潜在的ニーズが非常に大きいことを意味します。
日本では、日本語を生成するAIを開発している企業があります。エレクトロニクス企業のNECは8月にLLM cotomiを活用したサービスを開始した。通信会社NTTは、別のLLMであるtsuzumiをベースにしたサービスを3月に開始する予定。日本の携帯電話事業者ソフトバンクも独自のLLMを開発している。
ソフトバンクの宮川潤一社長は「日本の商習慣を理解することで、メールの返信やコールセンター業務をより自然に行えるなど、使い勝手の面で優位になる」と語った。
国産AIの開発競争を加速させているのは、特に国際競争力と国家安全保障に関して、米国への過度の依存のリスクだ。他国で開発されたAIプログラムを使用するとデータ漏洩が発生し、機密情報に影響を与えるのではないかという懸念もある。
ヴァン教授は、ますます多くの学生がAIを使って勉強しており、イノベーションが若い世代に大きな影響を与えていることを意味しているため、新興技術を外国企業に任せておくべきではないと述べた。
テクノロジーで米国と競争している中国では、百度、テンセントホールディングス、アリババグループホールディングが革新的なAIを開発している。百度のアーニーボットは昨年末時点で1億人を超えるユーザーを誇っている。
「現在開発中の生成大規模言語モデルは、中国語と中国市場にさらに適したものになるだろう」と百度の会長兼CEOであるロビン・リー氏は述べた。
昨年8月、韓国のウェブサービス企業ネイバーは、韓国語向けにカスタマイズされた合成AI「HyperClova X」を発表した。このプログラムは同社の検索エンジンとオンラインショッピングプラットフォームと統合され、ユーザーがより効率的に希望する結果を見つけられるようになる。
ネイバーによると、同社の韓国語データベースはChatGPTの韓国語データベースの6,500倍の大きさで、より自然な読みやすいテキストとスムーズな言語認識を実現しているという。
先月、シンガポールはインドネシア語、マレーシア語、タイ語に合わせた法学修士課程を開発する計画を発表した。しかし、こうした取り組みは、あまり使用されていない言語でのトレーニング可能なデータの不足や、そうしたモデルの開発の収益性などの課題に直面することになるだろう。

[広告2]
ソース




![[写真] 政治局決議第66-NQ/TW号および第68-NQ/TW号の普及と実施のための全国会議](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/5/18/adf666b9303a4213998b395b05234b6a)





























![[写真] ファム・ミン・チン首相が科学技術発展に関する会議を議長として開催](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/5/17/ae80dd74c384439789b12013c738a045)































































コメント (0)