
ຫລັງຈາກທີ່ຜູ້ເລີ່ມ OpenAI ໄດ້ເປີດຕົວແອັບພລິເຄຊັນ AI ທຳອິດ, ChatGPT, ໃນທ້າຍປີ 2022, ຄື້ນການແຂ່ງຂັນເພື່ອພັດທະນາແອັບພລິເຄຊັ່ນ AI ໄດ້ເກີດຂຶ້ນ, ໂດຍສະເພາະແມ່ນ AI ລຸ້ນສ້າງ, ນຳເອົາຄວາມສະດວກສະບາຍຫຼາຍຢ່າງໃນທຸກຂົງເຂດຂອງຊີວິດ. ຢ່າງໃດກໍຕາມ, ນີ້ຍັງນໍາເອົາຄວາມສ່ຽງຫຼາຍ.
ການບຸກລຸກຂອງຄວາມເປັນສ່ວນຕົວ
ໃນຊຸມປີມໍ່ໆມານີ້, ອົງການຈັດຕັ້ງແລະບຸກຄົນຈໍານວນຫຼາຍໄດ້ຮັບການສູນເສຍໃນເວລາທີ່ອາດຊະຍາກໍາທາງອິນເຕີເນັດໃຊ້ AI ເພື່ອສ້າງຄລິບວີດີໂອທີ່ປອມແປງຮູບພາບແລະສຽງຂອງຄົນທີ່ແທ້ຈິງ. ຕົວຢ່າງຫນຶ່ງແມ່ນ trick Deepfake.
ອີງຕາມບົດລາຍງານການສໍ້ໂກງຕົວຕົນທີ່ເຜີຍແຜ່ໂດຍ Sumsub ໃນທ້າຍເດືອນພະຈິກ 2023, ການຫລອກລວງ Deepfake ທົ່ວໂລກເພີ່ມຂຶ້ນ 10 ເທົ່າໃນປີ 2022-2023. ນີ້ແມ່ນເວລາຂອງການລະເບີດຂອງຄໍາຮ້ອງສະຫມັກ AI ປອມໃນໂລກ.
Status Labs ໃຫ້ຄໍາເຫັນວ່າ Deepfake ມີຜົນກະທົບອັນໃຫຍ່ຫຼວງຕໍ່ວັດທະນະທໍາ, ຄວາມເປັນສ່ວນຕົວແລະຊື່ສຽງສ່ວນບຸກຄົນ. ຂ່າວແລະຄວາມສົນໃຈຫຼາຍອ້ອມຂ້າງ Deepfakes ໄດ້ສຸມໃສ່ວິດີໂອ porn ທີ່ມີຊື່ສຽງ, porn revenge, disinformation, ຂ່າວປອມ, blackmail, ແລະການຫລອກລວງ. ສໍາລັບຕົວຢ່າງ, ໃນປີ 2019, ບໍລິສັດພະລັງງານໃນສະຫະລັດໄດ້ຖືກຫລອກລວງຈາກ $ 243,000 ໂດຍຜູ້ຫລອກລວງທີ່ປອມຕົວເປັນຮູບພາບແລະສຽງຂອງຜູ້ນໍາຂອງບໍລິສັດ, ຮຽກຮ້ອງໃຫ້ພະນັກງານໂອນເງິນໃຫ້ກັບຄູ່ຮ່ວມງານ.
ອົງການຂ່າວ Reuters ກ່າວວ່າໃນປີ 2023, ປະມານ 500,000 ເນື້ອຫາ Deepfake ໃນຮູບແບບວິດີໂອແລະສຽງໄດ້ຖືກແບ່ງປັນໃນທົ່ວເຄືອຂ່າຍສັງຄົມທົ່ວໂລກ. ນອກຈາກ Deepfakes ສໍາລັບຄວາມມ່ວນ, ມີ tricks ສ້າງໂດຍຄົນບໍ່ດີເພື່ອຫລອກລວງຊຸມຊົນ. ຄາດຄະເນວ່າໃນປີ 2022, Deepfake scams ທົ່ວໂລກເຮັດໃຫ້ການສູນເສຍເຖິງ 11 ລ້ານ USD.
ຜູ້ຊ່ຽວຊານດ້ານເຕັກໂນໂລຢີຫຼາຍຄົນໄດ້ເຕືອນກ່ຽວກັບຜົນກະທົບທາງລົບຂອງ AI, ລວມທັງສິດທິຊັບສິນທາງປັນຍາແລະຄວາມແທ້ຈິງ, ແລະຕື່ມອີກ, ການຂັດແຍ້ງດ້ານຊັບສິນທາງປັນຍາລະຫວ່າງ "ວຽກງານ" ທີ່ສ້າງໂດຍ AI. ຕົວຢ່າງເຊັ່ນ, ຄົນຫນຶ່ງຂໍໃຫ້ຄໍາຮ້ອງສະຫມັກ AI ເພື່ອແຕ້ມຮູບທີ່ມີຫົວຂໍ້ທີ່ແນ່ນອນ, ແຕ່ອີກຄົນຫນຶ່ງກໍ່ຂໍໃຫ້ AI ເຮັດເຊັ່ນດຽວກັນ, ເຊິ່ງເຮັດໃຫ້ຮູບພາບມີຄວາມຄ້າຍຄືກັນຫຼາຍ.
ນີ້ເຮັດໃຫ້ມັນງ່າຍສໍາລັບການຂັດແຍ້ງກ່ຽວກັບຄວາມເປັນເຈົ້າຂອງ. ຢ່າງໃດກໍ່ຕາມ, ມາຮອດປັດຈຸບັນ, ໂລກຍັງບໍ່ທັນໄດ້ຕັດສິນໃຈກ່ຽວກັບການຮັບຮູ້ລິຂະສິດສໍາລັບເນື້ອຫາທີ່ສ້າງໂດຍ AI (ການຮັບຮູ້ລິຂະສິດສໍາລັບບຸກຄົນທີ່ສັ່ງໃຫ້ AI ສ້າງສັນຫຼືບໍລິສັດທີ່ພັດທະນາຄໍາຮ້ອງສະຫມັກ AI).

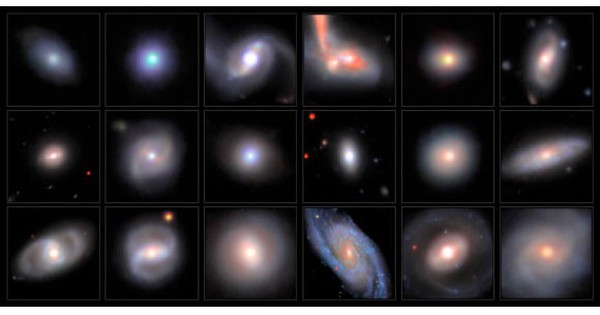
ຮູບພາບທີ່ສ້າງຂຶ້ນໂດຍແອັບພລິເຄຊັນ AI
ຍາກທີ່ຈະຈຳແນກລະຫວ່າງຂອງແທ້ ແລະ ຂອງປອມ
ດັ່ງນັ້ນເນື້ອຫາທີ່ສ້າງໂດຍ AI ສາມາດລະເມີດລິຂະສິດໄດ້ບໍ? ໃນດ້ານເທກໂນໂລຍີ, ເນື້ອຫາທີ່ສ້າງໂດຍ AI ໄດ້ຖືກສັງເຄາະໂດຍສູດການຄິດໄລ່ຈາກຂໍ້ມູນທີ່ມັນໄດ້ຮັບການຝຶກອົບຮົມ. ຖານຂໍ້ມູນເຫຼົ່ານີ້ແມ່ນເກັບກໍາໂດຍຜູ້ພັດທະນາແອັບພລິເຄຊັນ AI ຈາກຫຼາຍແຫຼ່ງ, ສ່ວນໃຫຍ່ແມ່ນມາຈາກພື້ນຖານຄວາມຮູ້ໃນອິນເຕີເນັດ. ວຽກງານເຫຼົ່ານີ້ຈໍານວນຫຼາຍໄດ້ຖືກລິຂະສິດກັບເຈົ້າຂອງຂອງເຂົາເຈົ້າ.
ໃນວັນທີ 27 ເດືອນທັນວາ 2023, The New York Times (USA) ໄດ້ຟ້ອງຮ້ອງ OpenAI (ກັບ ChatGPT) ແລະ Microsoft, ໂດຍອ້າງວ່າບົດຄວາມຂອງເຂົາເຈົ້າຫຼາຍລ້ານໄດ້ຖືກນໍາໃຊ້ເພື່ອຝຶກອົບຮົມ AI chatbots ແລະເວທີ AI ຂອງສອງບໍລິສັດເຫຼົ່ານີ້. ຫຼັກຖານແມ່ນວ່າມີເນື້ອຫາທີ່ສ້າງໂດຍ chatbots ຕາມຄໍາຮ້ອງຂໍຂອງຜູ້ໃຊ້ທີ່ຄ້າຍຄືກັນຫຼືຄ້າຍຄືກັນກັບເນື້ອຫາຂອງບົດຄວາມ. ຫນັງສືພິມນີ້ບໍ່ສາມາດບໍ່ສົນໃຈໃນເວລາທີ່ "ຊັບສິນທາງປັນຍາ" ຂອງພວກເຂົາຖືກນໍາໃຊ້ໂດຍບໍລິສັດເພື່ອກໍາໄລ.
ໜັງສືພິມ New York Times ເປັນໜັງສືພິມໃຫຍ່ແຫ່ງທຳອິດຂອງສະຫະລັດ ທີ່ຍື່ນຟ້ອງເລື່ອງລິຂະສິດທີ່ກ່ຽວຂ້ອງກັບ AI. ມັນເປັນໄປໄດ້ວ່າໃນອະນາຄົດອັນໃກ້ນີ້, ຫນັງສືພິມອື່ນໆຍັງຈະຟ້ອງ, ໂດຍສະເພາະຫຼັງຈາກຄວາມສໍາເລັດຂອງ The New York Times.
ກ່ອນຫນ້ານີ້, OpenAI ໄດ້ບັນລຸຂໍ້ຕົກລົງລິຂະສິດກັບອົງການຂ່າວ Associated Press ໃນເດືອນກໍລະກົດ 2023 ແລະ Axel Springer - ຜູ້ຈັດພິມເຍຍລະມັນທີ່ເປັນເຈົ້າຂອງສອງຫນັງສືພິມ Politico ແລະ Business Insider - ໃນເດືອນທັນວາ 2023.
ນັກສະແດງ Sarah Silverman ຍັງໄດ້ເຂົ້າຮ່ວມການຟ້ອງຮ້ອງຫຼາຍໆຄັ້ງໃນເດືອນກໍລະກົດ 2023, ໂດຍກ່າວຫາ Meta ແລະ OpenAI ວ່າໃຊ້ບົດບັນທຶກຂອງນາງເປັນຂໍ້ຄວາມຝຶກອົບຮົມສໍາລັບໂຄງການ AI. ນັກຂຽນຫຼາຍຄົນຍັງໄດ້ສະແດງຄວາມຕື່ນຕົວເມື່ອມີການເປີດເຜີຍວ່າລະບົບ AI ໄດ້ດູດເອົາຫນັງສືຫລາຍສິບພັນຫົວເຂົ້າໄປໃນຖານຂໍ້ມູນຂອງມັນ, ເຊິ່ງນໍາໄປສູ່ການຟ້ອງຮ້ອງຈາກຜູ້ຂຽນເຊັ່ນ Jonathan Franzen ແລະ John Grisham.
ໃນຂະນະດຽວກັນ, ການບໍລິການຮູບພາບ Getty Images ຍັງໄດ້ຟ້ອງບໍລິສັດ AI ໃນການສ້າງຮູບພາບໂດຍອີງໃສ່ການເຕືອນຂໍ້ຄວາມເນື່ອງຈາກການນໍາໃຊ້ເນື້ອຫາທີ່ມີລິຂະສິດຂອງບໍລິສັດທີ່ບໍ່ໄດ້ຮັບອະນຸຍາດ ...
ຜູ້ໃຊ້ສາມາດເຂົ້າໄປໃນບັນຫາລິຂະສິດໃນເວລາທີ່ພວກເຂົາ "ລະມັດລະວັງ" ໃຊ້ "ເຮັດວຽກ" ທີ່ພວກເຂົາໄດ້ຂໍໃຫ້ເຄື່ອງມື AI "ປະກອບ". ຜູ້ຊ່ຽວຊານສະເຫມີແນະນໍາໃຫ້ໃຊ້ເຄື່ອງມື AI ພຽງແຕ່ສໍາລັບການຄົ້ນຫາ, ເກັບກໍາຂໍ້ມູນ, ແລະຄໍາແນະນໍາສໍາລັບການອ້າງອີງເທົ່ານັ້ນ.
ໃນບັນຫາອື່ນ, ຄໍາຮ້ອງສະຫມັກ AI ເຮັດໃຫ້ຜູ້ໃຊ້ສັບສົນໃນເວລາທີ່ພວກເຂົາບໍ່ສາມາດຈໍາແນກລະຫວ່າງຄວາມຈິງແລະຄວາມຜິດຂອງເນື້ອຫາທີ່ແນ່ນອນ. ຜູ້ພິມແລະບັນນາທິການສາມາດສັບສົນໃນເວລາທີ່ມັນມາກັບການຍອມຮັບຫນັງສືໃບລານ. ຄູຍັງມີບັນຫາໃນການຮູ້ວ່າວຽກຂອງນັກຮຽນໃຊ້ AI ຫຼືບໍ່.
ໃນປັດຈຸບັນຊຸມຊົນຈະຕ້ອງມີຄວາມລະມັດລະວັງຫຼາຍຂຶ້ນຍ້ອນວ່າພວກເຂົາບໍ່ຮູ້ວ່າເນື້ອຫາໃດເປັນຂອງແທ້ແລະເນື້ອຫາໃດທີ່ປອມ. ຕົວຢ່າງ, ມັນຈະເປັນການຍາກສໍາລັບຄົນໂດຍສະເລ່ຍທີ່ຈະກວດພົບວ່າຮູບພາບໄດ້ຖືກ "ດຶງດູດໃຈ" ຫຼືແກ້ໄຂໂດຍ AI.
ກົດລະບຽບທາງດ້ານກົດຫມາຍກ່ຽວກັບການນໍາໃຊ້ AI ແມ່ນຈໍາເປັນ
ໃນຂະນະທີ່ລໍຖ້າເຄື່ອງມືຄໍາຮ້ອງສະຫມັກທີ່ສາມາດກວດພົບການແຊກແຊງຂອງ AI, ອົງການຈັດຕັ້ງການຄຸ້ມຄອງຈໍາເປັນຕ້ອງມີກົດລະບຽບທາງດ້ານກົດຫມາຍທີ່ຊັດເຈນແລະສະເພາະກ່ຽວກັບການນໍາໃຊ້ເຕັກໂນໂລຢີນີ້ເພື່ອສ້າງເນື້ອຫາສ່ວນຕົວ. ກົດລະບຽບທາງດ້ານກົດຫມາຍຈໍາເປັນຕ້ອງສະແດງໃຫ້ປະຊາຊົນຮູ້ວ່າເນື້ອຫາແລະວຽກງານໄດ້ຖືກແຊກແຊງໂດຍ AI, ສໍາລັບຕົວຢ່າງ, ໂດຍຄ່າເລີ່ມຕົ້ນ, ຮູບພາບທີ່ມີນ້ໍາທີ່ຖືກຫມູນໃຊ້ໂດຍ AI.
ທີ່ມາ: https://nld.com.vn/mat-trai-cua-ung-dung-tri-tue-nhan-tao-196240227204333618.htm





































![[ຮູບພາບ] ທ່ານນາຍົກລັດຖະມົນຕີ ຟ້າມມິງຈິ້ງ ເປັນປະທານກອງປະຊຸມລັດຖະບານກັບທ້ອງຖິ່ນກ່ຽວກັບການເຕີບໂຕເສດຖະກິດ](https://vstatic.vietnam.vn/vietnam/resource/IMAGE/2025/2/21/f34583484f2643a2a2b72168a0d64baa)






















































(0)